C-based Design: High-Level Synthesis with Vivado HLS
Course Description
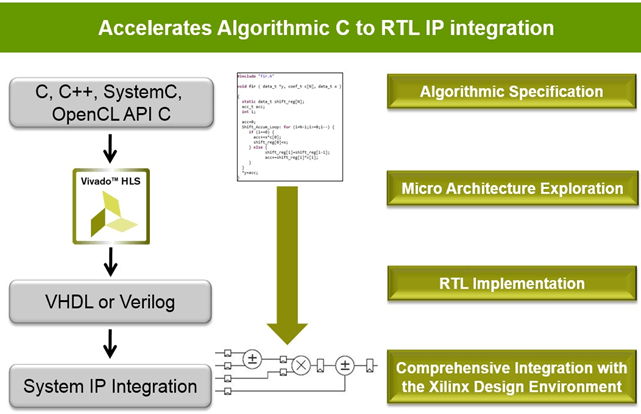
The course provides a thorough introduction to the Vivado® High-Level Synthesis (HLS) tool. This course covers synthesis strategies, features, improving throughput, area, interface creation, latency, testbench coding, and coding tips. Utilize the Vivado HLS tool to optimize code for high-speed performance in an embedded environment and download for in-circuit validation.
Level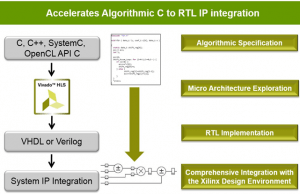
DSP 3
Course Duration
2 days
Who Should Attend?
Software and hardware engineers looking to utilize high-level synthesis
Prerequisites
- C, C++, or System C knowledge
- High-level synthesis for software engineers OR high-level synthesis for hardware engineers
Software Tools
- Vivado System Edition 2016.3
- SDSoC™ development environment 2016.3
Hardware
- Architecture: Zynq®-7000 All Programmable SoC and 7 series FPGAs*
- Demo board: Zynq-7000 All Programmable SoC ZC702 or Zed board* and Kintex®-7 FPGA KC705 board
* This course focuses on the Zynq-7000 All Programmable SoC and 7 series FPGA architectures. Check with your local Authorized Training Provider for the specifics of the in-class lab board or other customizations.
Skills Gained
After completing this comprehensive training, you will know how to:
- Enhance productivity by using the Vivado HLS tool
- Describe the high-level synthesis flow
- Use the Vivado tool HLS for a first project
- Identify the importance of the testbench
- Use directives to improve performance and area and select RTL interfaces
- Identify common coding pitfalls as well as methods for improving code for RTL/hardware
- Perform system-level integration of IP generated by the Vivado HLS tool
- Describe how to use OpenCV functions in the Vivado HLS tool
Course Outline
Day 1
- Introduction to High-Level Synthesis and the Vivado HLS Tool
- Using the Vivado HLS Tool: GUI Flow
- Demo: Vivado HLS Tool Overview
- Lab 1: Introduction to the Vivado HLS Tool Flow
- Lab 2: Introduction to the Vivado HLS Tool CLI Flow
- I/O Interfaces
- Demo: AXI-4 Stream Interfaces
- Lab 3: Interface Synthesis
- Pipelining for Performance
- Demo: Pipelining for Performance
- Lab 4: Improving Performance
Day 2
- Optimizing Structures for Performance
- Demo: Handling Memories
- Lab 5: Implementing Arrays as RTL Interfaces
- Reducing Latency
- Improving Area
- Lab 6: Improving Area and Resource Utilization
- Introduction to the HLx Design Flow
- Demo: Using Vivado HLS IP with SysGen
- Lab 7: HLx Flow – System Generation
- HLS vs. SDSoC Development Environment Flow
- Demo: SDSoC Tool Overview
- Vivado HLS Tool: C Code
Lab Descriptions
- Lab 1: Introduction to the Vivado HLS Tool Flow – Utilize the GUI to simulate and create a project. Perform RTL synthesis, verification, and exporting the C design as an IP.
- Lab 2: Introduction to the Vivado HLS Tool CLI Flow – Utilize a make file to perform C simulation. Create a project and perform C synthesis, RTL verification, and RTL packaging.
- Lab 3: Interface Synthesis – Analyze the default RTL interfaces and apply the INTERFACE directive to define the interface type.
- Lab 4: Improving Performance – Optimize loop performance and modify pipelining and its effect on performance. Apply the DATAFLOW directive to execute the pipeline task concurrently.
- Lab 5: Implementing Arrays as RTL Interfaces – Analyze the impact of manipulating arrays. Utilize directives to choose the type of memories to be implemented for the arrays.
- Lab 6: Improving Area and Resource Utilization – Observe the impact of various directives on resource utilization and performance.
- Lab 7: HLx Flow – System Integration – Set up an embedded design, create an HLS IP with the AXI Lite interface, import the IP into the embedded design, and validate the system on the demo board.
![]()
Datum
23 oktober 2017 - 24 oktober 2017
Locatie
Core|Vision
Cereslaan 24
5384 VT
Heesch
Prijs
€ 0,00
of
18 Xilinx Training Credits
Informatie
Training brochure
Registratieformulier
Registratie op aanvraag, neem contact op met ons.